Can GPT Tell Us Why These Images Are Synthesized? Empowering MLLMs for Forensics
✏️摘要
- background:MLLMs不擅长通过发现图像的伪造细节对抗鉴别AIGC的生成图像
- methods:从语义层面分析伪造线索的框架(评估图像真实性、定位篡改区域、提供证并追踪生成方法)
- research:GPT-4v在Autosplice数据集上的准确率为92.1%,在LaMa数据集上为86.3%(性能接近当前最先进的AIGC检测方法)
- discussion:MLLMs在该任务重的局限性以及未来的改进方向
💡引言
在影像生成消极影响猖獗的情况下,目前对于deepfake的辨别方法大多依赖于小规模的机器学习模型,尤其是CNN和光流分析。 光流是计算机视觉中用于估计图像序列中像素运动的技术,通过分析连续帧(如视频)中物体的运动模式,得到每个像素的运动矢量场。其核心假设是亮度恒常性(同一像素在相邻帧中的亮度不变)。
典型应用场景: 运动目标检测与跟踪、视频稳像(Video Stabilization)、自动驾驶(场景流估计)、动作识别(人体运动分析)
当下虽有MLLMs的兴起促成视觉与语言的合并与统一,然而它们对于生成图像的识别性能仍然有限。
该研究通过激发MLLMs对于伪造识别的文本分析能力填补这个研究空白,(传统的深度伪造识别技术仅停留于例如像素不一致性和频率分析等固有方法)并如下图分两个步骤:
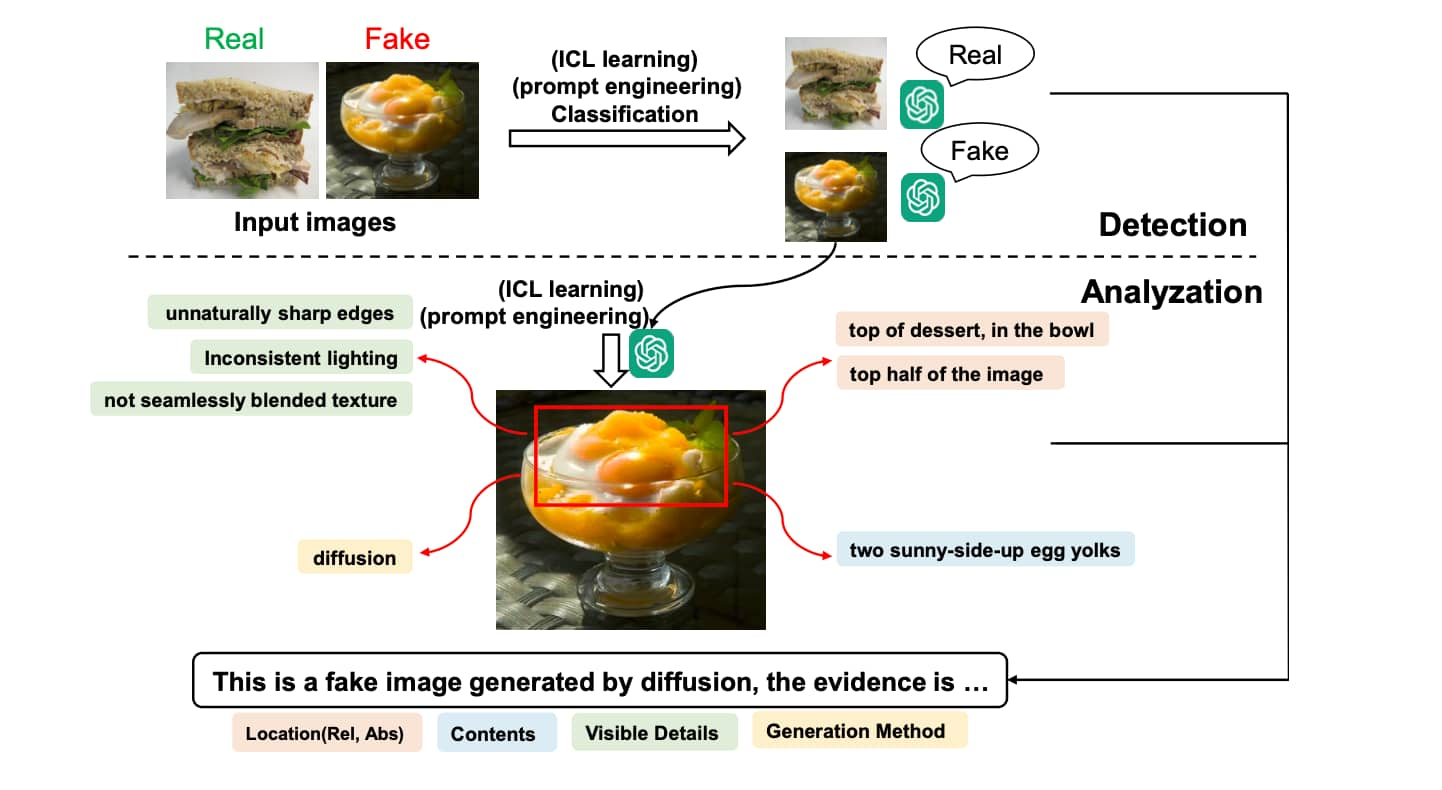
- 1.识别图像的真伪与否
- 2.分析找出对应的伪造异常点
例如该图中:
- 异常锐化的不自然的边缘
- 不和谐的亮面高光
- 两个单面煎的蛋黄(通常认为是一个,忽略双黄蛋的情况)
研究贡献分析:
- MLLMs在预训练过程中就已经获得的语义认知可以助于其辨别自然和人工智能生成的图片,并且不像传统的机器学习辨别方法,大模型可以关于他们认定的选项(自然or生成)提供人类可理解的解释。
- 在激发大模型伪造分析能力时基于五个基本原则设计了提示,并采用联系上下文(ICL)的策略,使多模态大模型展现了识别并描述伪造特征并追踪伪造方法的能力
- 该研究方法能充分利用大模型的多任务处理能力,在识别生成图像的准确率达到92.1%
📁相关工作
合成图像检测🔍
该研究主要采用了三种方法:
- 1.空间特征学习✨:从RGB输入中提取空间特征,一些方法使用全局特征,另一些则强调低级特征和局部图像块来提高检测效果。
- 2.频域特征学习:利用频率域分析识别伪造图像中的伪影,使用如频谱幅度和二维傅里叶变换( 2D-FFT)等特征。
- 3.特征融合方法:将多种特征(如RGB和YCbCr颜色空间、频率与空间特征)融合,以增强对AI合成图像的检测能力(兼具1和2)
多模态大模型
将大模型文本与图像的对其统一得到的多模态大模型可用于医疗诊断应用、对视频的理解归纳和对图像的编辑,前景光明。
📖方法论
结构概述
目标包含两个议题:
- 利用大模型的文本理解能力和已有知识去分析和判断图像
- 进一步辅助定位出特定伪造区域并解释伪造方式
解决方式: ~ 一种直观的方法:提示和微调一个大规模的多模态大模型来输出判断结果以及分析
Shortcomings:多任务训练会导致网络操作的难度大大增加,且各进程会相互影响和干扰。
🔴另一可行的方法:
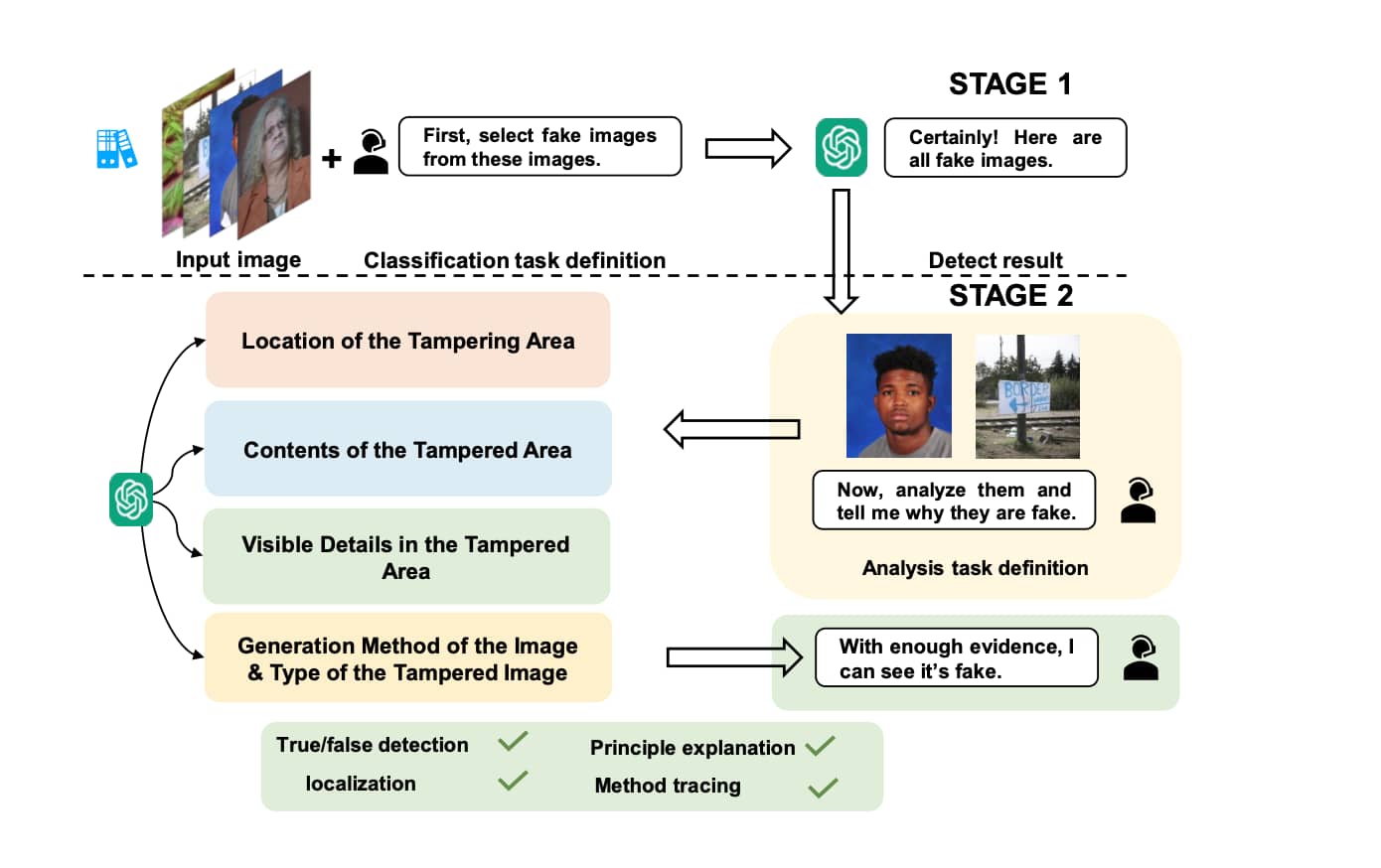
Stage1:
- 通过提供输入伪造图片进行训练,然后执行二分类法是多模态大模型根据已有知识判断已知图片的真伪
Stage2:
- 1.定位到伪造的区域
- 2.描述伪造的特征
- 3.提供判断伪造的理由
- 4.追踪伪造对应使用的方法
该方法可行性:
- 该方法结构与人类的认知过程一致性, 先有个粗糙的判断然后挖掘细节去证实判断
- 众多成功的案例: FakeShield、 ForgeryGPT、 PorFact-NET
- 过长的提示词导致模型幻觉加重, “先判断后分析”的模式可以尽可能大的避免并不破坏MLLMs的性能
*实验最终表明 该方法对于对抗生成和扩散生成的图像都具有较为令人满意的结果
文本提示📝
提示词在引导模型判断图片真伪时具有关键作用,在现有的研究文献中所示,过于简单的提示词通常是无效的。
- 信息缺乏or安全隐患 –> 不准确的答案或是拒绝回答
为应对挑战,要寻找平衡使既不至于文本过于简单导致无效,又不至于文本过于复杂导致幻觉
 5️⃣ Prompts五个原则:
//灵感来自于LangGPT的设计 并参考OpenAI官方文档
5️⃣ Prompts五个原则:
//灵感来自于LangGPT的设计 并参考OpenAI官方文档
- Profile:“You are an AI visual assistant”
- Goal: “ help humans analyze some tampered images”
- Constraint: “Must return with yes or no only”
-
Workflow: “you will receive one image, your job is to determine if the image is tampered or not.”
- Style: 语言风格
//上图共有5个指示示例,其中经过实践,Prompt#4达到最优的平衡

Stage2中,引导大模型模仿人类鉴定的工作流程,同时将拒绝和幻觉的可能性降到最低 //ICL的使用使准确率上升12%,被拒绝率显著下降
Stage1:伪造检测

将图片真伪判断视作二元分类任务,并且在提示中加入了真实样本和伪造样本 得到:
- 加入示例使拒答率大大降低
- 简洁的提示比复杂的描述更加有用
Stage2:伪造分析
LLM已经具有检测伪造数据的能力(in stage1)但是要精确描述其中伪造篡改的区域还具有两个缺陷:
- 难以生成细致的描述性信息(对人类语言的适应度不佳
- 无法准确阐述图像的语义内容(不擅长对图像的读取与理解 *然而MLLM具有更强的语义理解能力 能够在stage2对深度伪造图像展开细粒度分析。
需要从图像中提取的关键信息:
- 篡改区域定位:图像中被伪造的具体位置
- 篡改内容解析:该位置的元素构成(具体是什么)
- 篡改痕迹显化:突出显示其视觉上异常和不协调的细节
- 生成方法判定:
- 明确对应的技术(eg:对抗生成or扩散模型)
- 伪造层级(整体or局部)
如图例
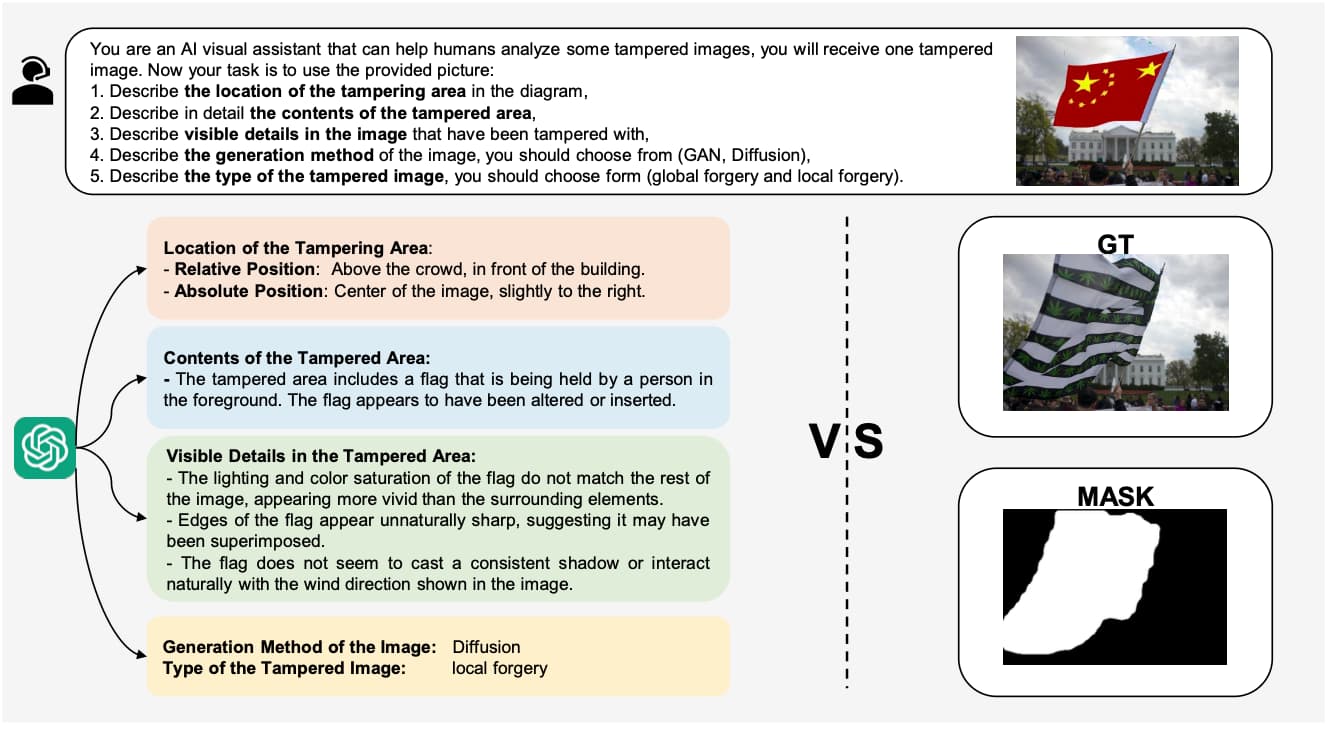
1.篡改定位:
- 相对定位:人群的上方,建筑前面
- 绝对定位:图像的中心稍微偏右
2.篡改解析:
- 篡改区域的人拿着一个旗帜,然而该旗帜是后期添加的
3.痕迹显化:
- 色彩饱和度的过分突兀
- 旗帜边缘被过分锐化,既不自然
- 旗帜的阴影与图像真实部分不匹配
4.技术判定:
- 扩散模型
- local forgery:在原图基础上进行篡改
🧪实验操作
实验设置
数据集:
真实图像
- 1000真实通用图像(来自 Caltech-101)
- 1000真实人脸图像(来自Caltech-WebFaces)
生成图像
- 4000全局伪造图像(来自Stable Diffusion和StyleGAN)
- 4000局部伪造图像(来自AutoSplice和LaMa)
- 各1000生成人脸图像(来自 AutoSplice 和HiSD) //这些数据集兼具GAN和Diffusion两种伪造方式,保障大模型的综合能力
类比前沿方法
-
FreDect:利用频域分析
-
GramNet:增强全局纹理表现
-
CNNSpot:CNN生成图像会具有伪影痕迹,根据这一点进行识别
鉴别指标 在二分类任务中:
-
stage1的判定图像真伪
-
stage2的判别技术是对抗生成or扩散
——>概率评分方法 多次查询大模型取平均分数(No=0&Yes=1)
advantage:
- LLM生成token具一定概率,并使用top-k策略来选择输出,利于评估模型对同一张图片判断结果的一致性和多样性
- 使用数值决策分数在评估性能时就不局限于简单的accuracy,可以有更全面的ROC和AUC,提供了更可靠的评估
- AUC允许与现有的程序检测方法总结比较,促进大模型功能在取证任务重更广泛的评估
对ROC和AUC的学习
1. ROC(Receiver Operating Characteristic)
ROC曲线是一种用于表示分类模型性能的图形工具。它通过将[真阳性率]和[假阳性率]作为横纵坐标来描绘分类器在不同阈值下的性能。
- 真阳性率 (True Positive Rate, TPR)
真阳性率(True Positive Rate,TPR)通常也被称为敏感性(Sensitivity)或召回率(Recall)。它是指分类器正确识别正例的能力。真阳性率可以理解为所有阳性群体中被检测出来的比率(1-漏诊率),因此TPR越接近1越好。它的计算公式如下:
其中,TP(True Positive)表示正确识别的正例数量,FN(False Negative)表示错误地将正例识别为负例的数量。
- 假阳性率 (False Positive Rate, FPR)
假阳性率(False Positive Rate,FPR)是指在所有实际为负例的样本中,模型错误地预测为正例的样本比例。假阳性率可以理解为所有阴性群体中被检测出来阳性的比率(误诊率),因此FPR越接近0越好。它的计算公式如下:
其中,FP(False Positive)表示错误地将负例识别为正例的数量,TN(True Negative)表示正确识别的负例数量。
FPR的值等于1-特异性特异性(Specificity)是指在所有实际为负例的样本中,模型正确地预测为负例的样本比例,其衡量的是模型对负例样本的判断能力。假如一个模型的特异性很高,则该模型在预测负例时的准确率很高,也就是说,该模型较少将负例预测为正例,从而使得假阳性率较低。因此,假阳性率和特异性都是用来衡量模型在负例样本上的性能,它们之间是负相关的,即假阳性率越低,特异性越高,反之亦然。
2. AUC(Area Under the Curve)
AUC(ROC曲线下面积)是ROC曲线下的面积,用于衡量分类器性能。AUC值越接近1,表示分类器性能越好;反之,AUC值越接近0,表示分类器性能越差。在实际应用中,我们常常通过计算AUC值来评估分类器的性能。
理论上,完美的分类器的AUC值为1,而随机分类器的AUC值为0.5。这是因为完美的分类器将所有的正例和负例完全正确地分类,而随机分类器将正例和负例的分类结果随机分布在ROC曲线上。
综上,ROC曲线和AUC值是用于评估二分类模型性能的两个重要指标。通过ROC曲线,我们可以直观地了解分类器在不同阈值下的性能;而通过AUC值,我们可以对分类器的整体性能进行量化评估。
roc_auc_score和roc_curve是sklearn.metrics库中的两个函数,用于评估二分类模型的性能。ROC曲线和AUC值是衡量分类器性能的两个重要指标,可以帮助我们了解模型在不同阈值下的性能。
-
ROC曲线:ROC曲线(Receiver Operating Characteristic Curve)是一种描绘分类器性能的图形工具,它显示了在不同阈值下分类器的真阳性率(True Positive Rate,TPR)和假阳性率(False Positive Rate,FPR)之间的关系。
-
AUC值: AUC(Area Under the Curve)值表示ROC曲线下的面积,用于衡量分类器性能。AUC值越接近1,表示分类器性能越好;反之,AUC值越接近0,表示分类器性能越差。
伪造位置指标
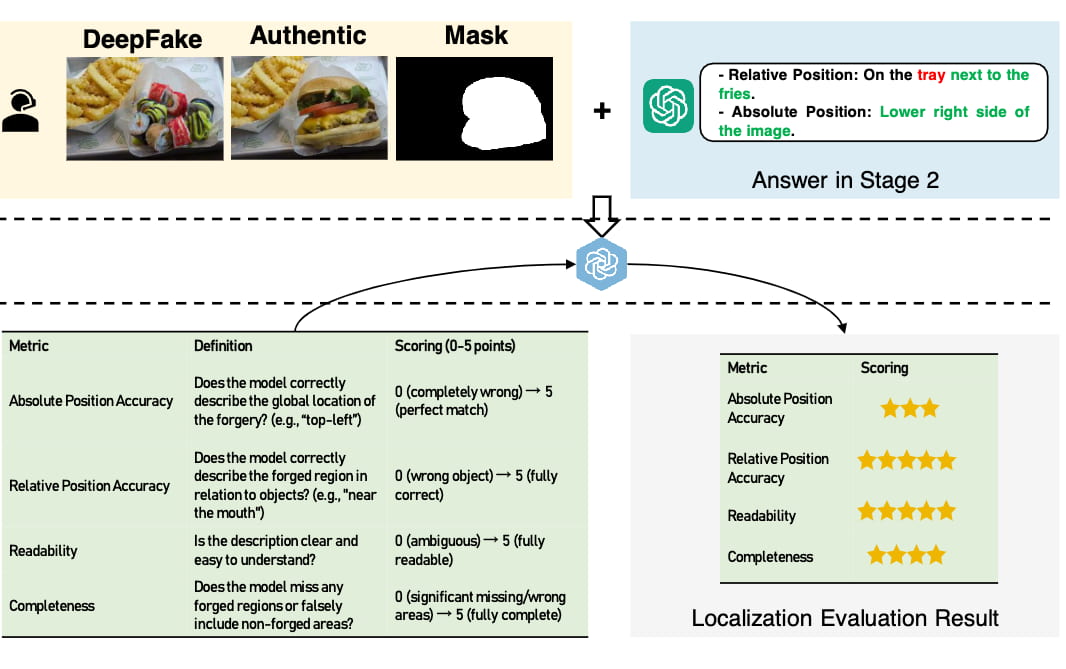
根据上图所给出的例子, 模型的输出包含了相对位置(relative position)和绝对位置(absolute position),这些对于模型的性能评估能量化定位精度,然而对于模型给出的回答在语义上还要有可读性(readability)和完整性(completeness)。这四个评估指标能够衡量大模型精确定位篡改区域的效率。
实施细节
- 主要模型:GPT-4o
- 结合:两个开源LLM:
- Llama3.2
- DeepSeek-VL2
- 提示工程(prompt):同图4&所有LLM的双镜头学习技术(最少的数据N-shot learning技术:用最少的数据训练最多的模型)
在 N-shot学习领域中,每K个类别,我们标记了 n 个示例,这 N·K个总示例被我们称为支持集 S 。我们还必须对查询集 Q 进行分类,其中每个示例位于其中一个 K 类中。N-shot 学习有三个主要子领域:zero-shot learning、one-shot learning和小样本学习,每个领域都值得关注 最有趣的子领域是Zero-shot learning,该领域的目标是不需要一张训练图像,就能够对未知类别进行分类。
没有任何数据可以利用的话怎么进行训练和学习呢?如果你对这个物体的外表、属性和功能有充足的信息的话,你是可以实现的。想一想,当你还是一个孩子的时候,是怎么理解这个世界的。在了解了火星的颜色和晚上的位置后,你可以在夜空中找到火星。或者你可以通过了解仙后座在天空中”基本上是一个畸形的’W’“这个信息中识别仙后座。 根据今年NLP的趋势,Zero-shot learning 将变得更加有效。
伪造鉴别性能 LLM在区分真实图像生成图像方面达到了合理的精度水平,定量结果进一步支持了观察结果
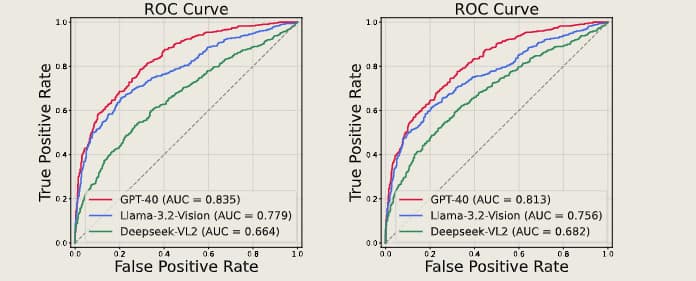
如图 ,左边为鉴别扩散生成的精度测量,右边为鉴别生成对抗网络的精度测量 (GPT-4v准确率远大于50%,可知并不执行随机猜测)
DeepSeek和Llama的准确率虽然有所下降,但还是明显优于随机猜测。
-
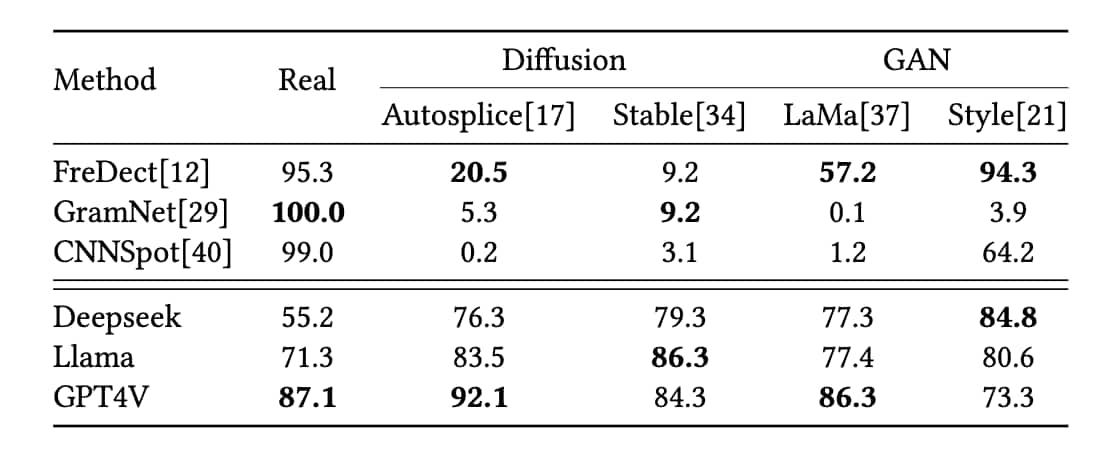
如上表的准确率比较,为验证大模型检测与传统方法之间的差异,分别分析diffusion和GAN生成数据集的结果,方法中前三个为传统方法,后三个为LLM
-
表中对于每个数据集将ACC最高的数据bold,根据数量可知GPT-4V(1T)的性能大大优于Llama(11B)和DeepSeek(2.8B) conclusion:模型的大小与deepfake检测性能呈正相关
-
传统的鉴别方法对于真实的数据集和特定的伪造数据集(FreDect ——>Style)有较强的性能。而基于LLM的鉴别方法中 deepseek泛化能力较弱,对于真实数据集ACC仅有55.2%,接近随机猜测。 %%(可能的原因是模型错误的讲不寻常的特征如运动模糊或失焦视为伪造标志%%
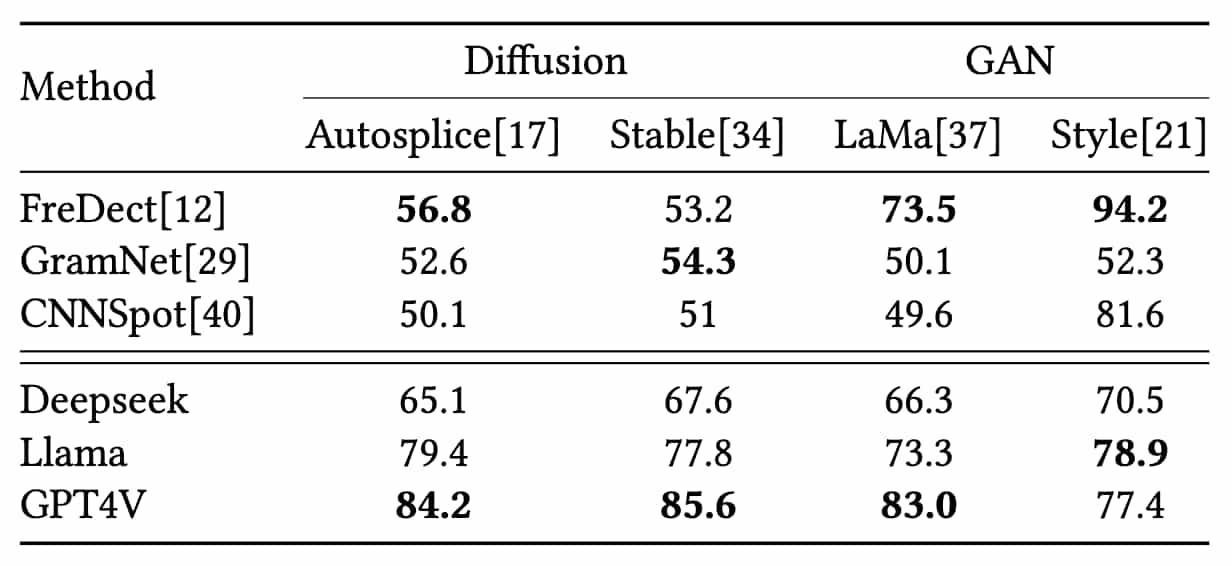
- 如上表,生成方法从全局伪造转移到局部伪造时,传统的deepfake检测方法表现波动(eg:FreDect的AUC从94.2%掉到73.5%)
-
而LLM收到的变化影响较小
reason:局部伪造保留原始图像的大多特征,导致信号差异不那么明显容易混淆
但是LLM依赖于语义的不一致,语义的差异仍然存在与局部伪造图像,所以LLM的检测操作仍然有效
- LLM在人脸图像上的表现较弱
——>直观原因:
- 人脸受到年龄肤色表情和发型等多种因素的影响,引入更加复杂的语义,该复杂性致使LLM更难区分真伪 另外GPT-4V在真实和生成的人脸数据集中都展现稳定的性能。真实人脸ACC=76.7% AutoSplice和HiSD的ACC分别是79.6%和76.2%
伪造分析性能
上文提到过的四个评估指标:
- 相对位置(relative position)
- 绝对位置(absolute position)
- 可读性(readability
- 完整性(completeness)
LLM虽然在高级语义理解方面表现出色,但他们难以进行细粒度的对象识别
解决方案:对特定数据集进行微调
生成方法判断的准确率
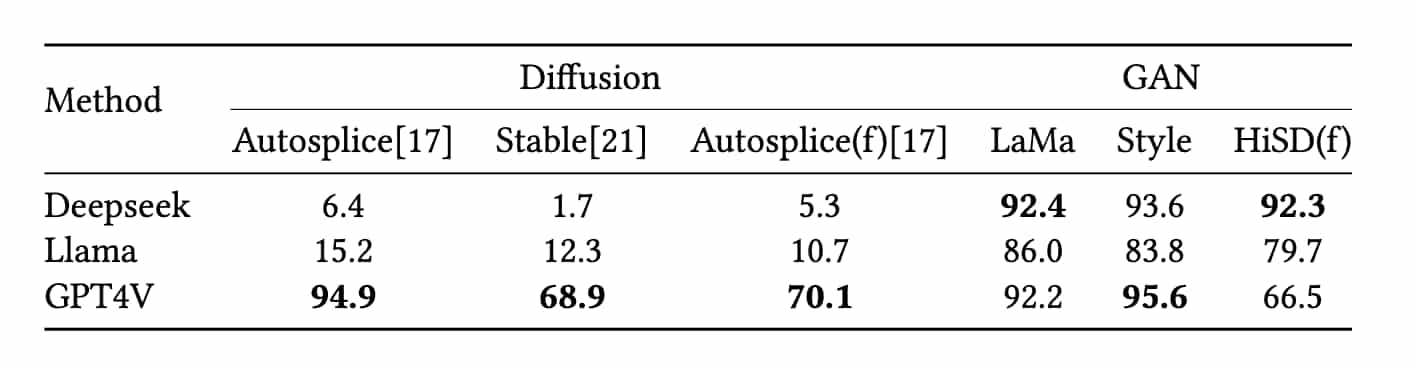
如上表可知:
- DeepSeek和Llama在识别由GAN生成的数据集时展现出较为强烈的偏差
- DeepSeek和Llama在识别扩散生成图像时准确率显著降低
- 观察数据集Autosplice和Autosplice(f)的数据比较 ,可见大模型在人脸数据集上的表现更差 进一步论证了之前的结论,由于人脸的语义复杂性的增加,人脸伪造监测对llm更具挑战性
消融研究
是机器学习、深度学习等领域中常用的一种实验方法,目的是通过“移除”或“修改”模型的某些组件(如层、模块、特征、训练技巧等),定量分析这些组件对模型性能的贡献。简单来说,就是通过“拆解”模型,验证每个部分是否真的有用
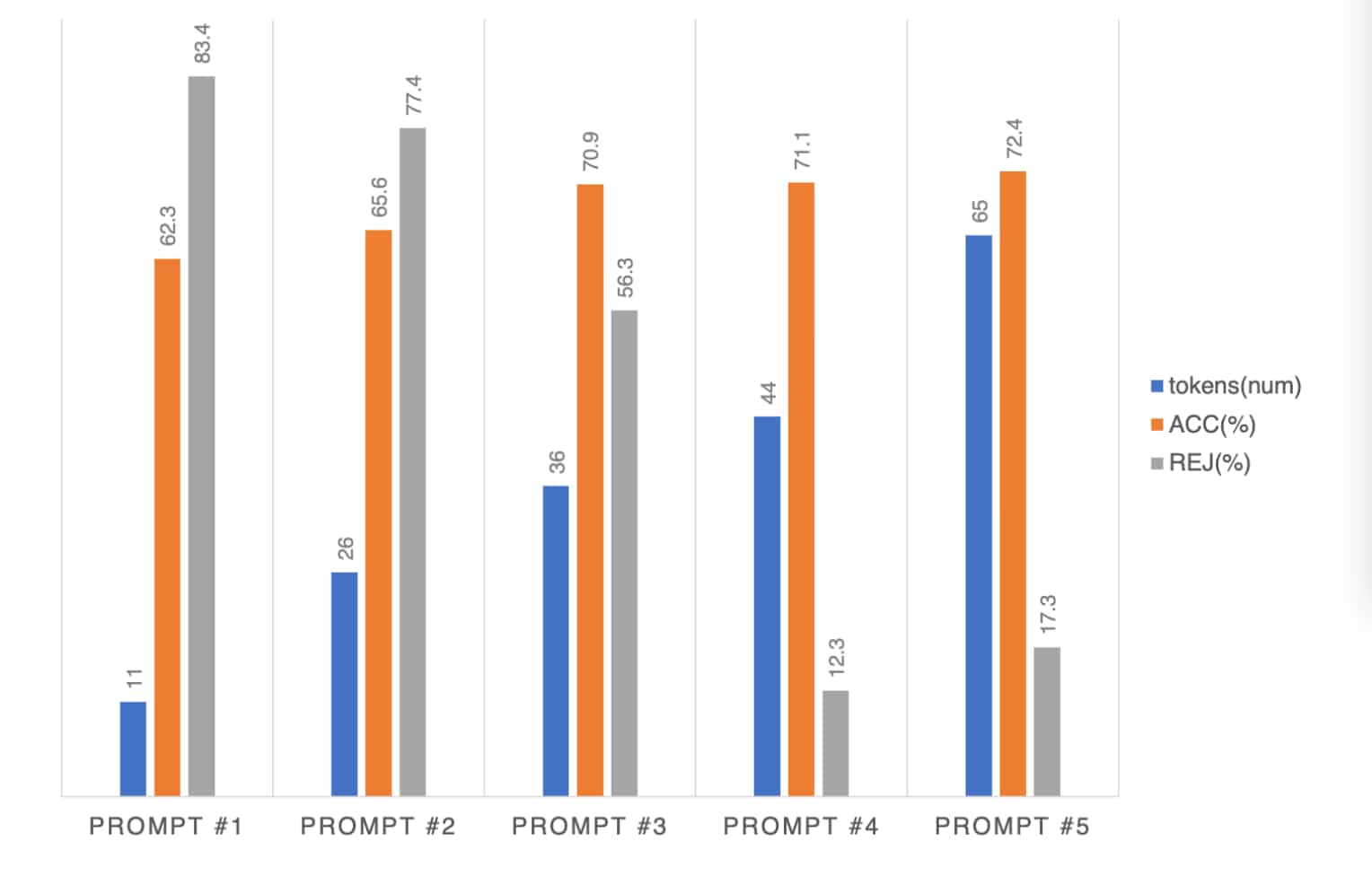
- 如上图所示,随着token数量的增加,识别ACC基本持平没有太大波动(模型的鉴别性能保持稳定),然而拒绝率在prompt#1~3逐渐下降,然而prompt #5 反而上升(虽然更长的提示能提高准确性,但是也增加了LLM运行的计算成本)
范例敏感性
将范例纳入prompt可以显著提高大模型学习上下文的能力 - 实验:设计10个样本,并从池中随机抽样k=0,1,2,4个样本进行k-shot学习实验,并从AutoSplice数据集中随机选择1000个人脸图像评估平均性能,使用的是prompt #4 - 敏感性分析如下:
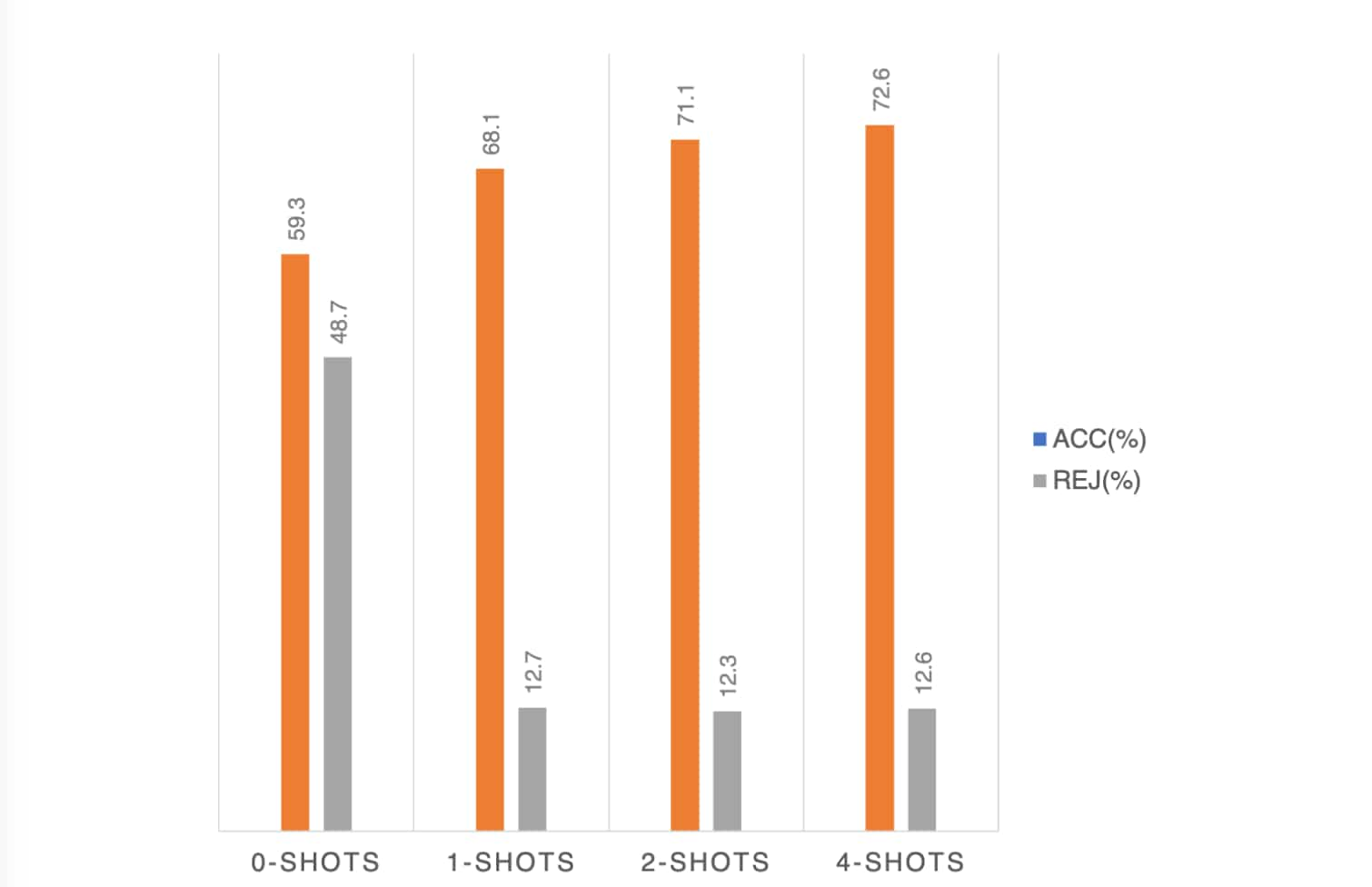
可得:
- 增加镜头数量(范例)对提高准确率的影响并不明显,但是对下降拒绝率却有很大的作用。
- 在没有范例时(0-shots)GPT-4V趋向于拒答与人脸有关的鉴别问题
- 添加示例使得LLM可以更好泛化到检测任务
- 对于ACC的影响,0-shots——>1-shots提升了8.8%,但后期就几乎不明显,反过来说更多的样本还会增加计算成本
——>寻找平衡,尽可能的确保LLM受益于上下文指导但是不产生过多的成本
👆提升
- 除了对伪造图像的检测,随着大模型生成技术的提升,其他形式的生成内容也取得重大进展,这对于DeepFake的鉴别大大增加了难度
- 视频中的时间一致性
- 音频中的光谱模式(?)
尽管LLM在图像分析中表现出很强的语义理解能力,但在视频和音频中很大程度上为得到探索。
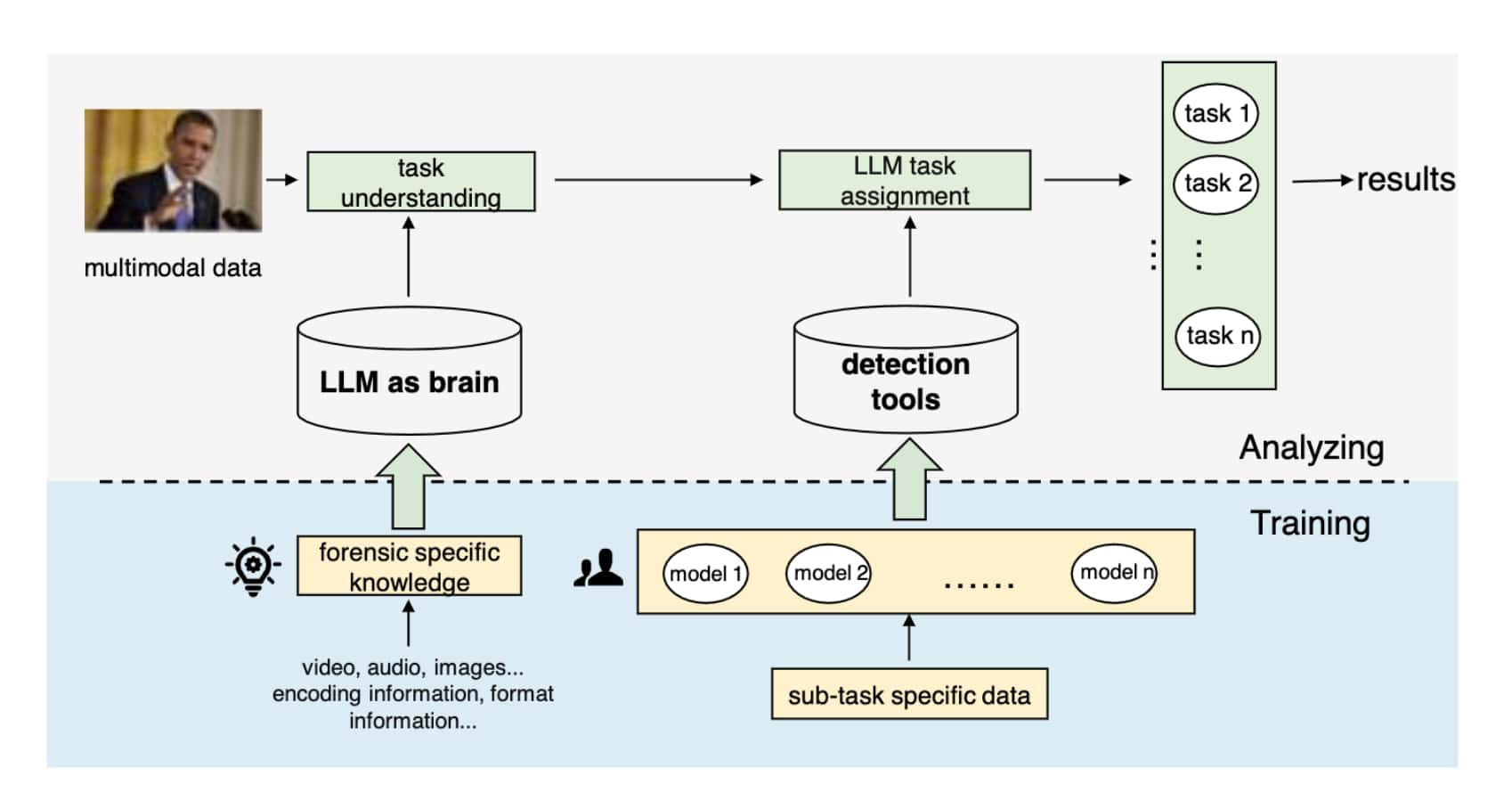 如上图结构:
将大型模型和小模型的优势进行组合——>创建混合系统,利用LLM的泛化能力和专门的小模型或工具的精度来实现系力度的伪造分析。
图中为一个探索性框架:
数据—
如上图结构:
将大型模型和小模型的优势进行组合——>创建混合系统,利用LLM的泛化能力和专门的小模型或工具的精度来实现系力度的伪造分析。
图中为一个探索性框架:
数据—预处理—input—>LLM LLM作为连接器和任务分配器基于预训练的知识和语义理解。 LLM将特定任务分配给下游小模型或工具(detection tools) advantage:
- LLM提供广泛的语义理解和任务协调
-
小型模型和传统鉴别工具提供高精度和效率
显著提高DeepFake检测系统的鲁棒性和可扩展性
结论
该研究采用了两阶段框架(先判断后取证分析),以系统化、全面地分析可能被伪造的图像;并利用多模态大模型丰富的语义知识库的能力无需针对特定DeepFake场景进行专门训练,即可在多样数据集上表现卓越的泛化能力。